Una rivoluzione è alle porte. Si chiama ‘data democratization’ e rischia di renderci davvero più liberi.

Massimiliano Cavallo, cofondatore di Hicare, la società che ha introdotto gli ‘ipercubi’ nella Business Intelligence, ci racconta perché insieme ai suoi partner sta per lanciare ‘Toronto’, un’applicazione BI alla portata di tutti (o quasi)
Intervista a cura di M. Morelli
È sempre bello partire dall’inizio, dagli albori. Tanto tempo fa, quand’ero giovane e si cominciava a parlare di reti neurali, i DSS (Decision Support Systems) erano molto in voga. Allora il termine ‘intelligenza artificiale’ sembrava vago, generico, mentre per le applicazioni concrete si parlava spesso, per l’appunto, di ‘sistemi di supporto alle decisioni’. In un tuo articolo recente hai fatto un interessante parallelo tra le vicende della Business e della Artificial Intelligence. Hai voglia di fare un piccolo excursus su come sono nati i sistemi di supporto alle decisioni, che tecnologie impiegavano, e che tipo di relazione avevano con la più ampia classe delle applicazioni AI?

Massimiliano Cavallo
Max Cavallo: Quando iniziai a lavorare si parlava non solo di DSS ma anche di Executive Information Systems (EIS), come se fossero due cose distinte. E in effetti lo erano: i DSS avevano lo scopo di fornire a chi doveva prendere decisioni un supporto informativo solido, mentre gli Executive Information System afferivano all’area della governance aziendale che aveva bisogno di visualizzare in modo efficace l’andamento dell’impresa. Da un lato era un supporto anche operativo, dall’altro una vera e propria ‘storia’ di quello che stava succedendo nelle aziende.
I due ambiti erano separati: mentre il DSS poteva essere molto tecnico e richiedere competenze specialistiche, gli Executive Information Systems dovevano essere semplici e graficamente diretti, efficaci per la governance; erano concepiti per essere utilizzati da manager non troppo alfabetizzati tecnicamente. L’Executive Information System era sostanzialmente un sistema di infograficizzazione dei dati, quello che oggi chiamiamo dashboard o tableau de bord – ovvero il reporting nella sua manifestazione più raffinata e interattiva.
Queste due discipline, DSS ed EIS si sono poi fuse in un’unica definizione: Business Intelligence. Purtroppo questa espressione è stata molto fraintesa, perché alcuni hanno continuato a considerarla come mero reporting, altri come lavorazione di dati propedeutici all’assunzione di decisioni rilevanti.
Una definizione corretta di Business Intelligence fa riferimento a una disciplina che unisce metodi, tecnologie e competenze per creare un substrato informativo propedeutico alle decisioni, che possa anche raccontare a consuntivo e prospetticamente quello che l’azienda può fare per conseguire valori sostenibili. La BI è una disciplina completa, non solo metodi, tecnologie o competenze, ma tutto questo in un unico set di applicazioni.
Questi sono sistemi che richiedono parecchie expertise per essere utilizzati. Se mi mettessi in testa di usare un’applicazione di Business Intelligence oggi, non saprei da che parte cominciare. I sistemi AI hanno invece la pretesa di aiutarti from scratch, anche se non sai ancora nulla…
Max Cavallo: È esattamente lì che voglio arrivare. La Business Intelligence richiede competenze di modellazione, di analisi dei dati, di comprensione di cos’è un metadato, c’è tutta una grammatica e una sintassi con cui è necessario acquisire familiarità.
Ma andiamo per ordine. Facciamo un passo indietro sul machine learning e le reti neurali. All’epoca quando si parlava di DSS e EIS si parlava anche di reti neurali e sistemi esperti. Voglio chiarire questo aspetto perché è ancora valido, anche se l’intelligenza artificiale che è in voga oggi si basa su principi di Large Language Model. La tecnologia di base è la stessa, ma diciamo che l’interpretazione degli LLM è un po’ diversa.
I sistemi di Business Intelligence di cui parli sono sistemi esperti o applicazioni di machine learning?
Max Cavallo: Bisogna vedere se abbiamo in mente le stesse distinzioni concettuali. Comincio a spiegare le mie. Nella divisione che ho in testa io, l’informatica è nata sulla spinta di Ted Codd e Christopher Date, due tecnici dell’IBM che hanno creato i primi database relazionali secondo lo schema entity-relationship che andava a creare repository di informazioni. Si sono creati due mondi: quello dei sistemi per il supporto alle decisioni e delle reti neurali, e quello legato alla modellazione con grammatica gerarchica, multidimensionale, relazionale, ovvero la componente di Codd e Date, legata a modelli spiegabili e ben definiti.
In quali situazioni erano applicabili i modelli ‘spiegabili’? Su strutture di dati chiare, ripetitive, laddove era presente una ciclicità di fenomeni: le stagioni, gli esercizi contabili commerciali, quelle cose lì. L’informazione è stata storicizzata in formato transazionale: veniva creata la transazione, il record, la memoria, poi quella transazione veniva registrata in una tabella e quei dati venivano poi letti in modo consuntivo con delle query SQL, che conferivano un’informazione completa.
Ripetiamolo: tutto questo funzionava dove c’era una ripetitività dei pattern. Al contrario dove non c’era ripetitività, come ad esempio in finanza, questo approccio non funzionava. Certo, esiste l’analisi tecnica che identifica delle tendenze, ma la realtà è che non sai mai esattamente cosa succede il giorno dopo. Non puoi mettere in piedi un modello di analisi perché non esiste un pattern di riferimento certo.
E allora ecco che i sistemi di supporto decisionale si sono differenziati: da un lato quelli che operavano dove c’era una certa ciclicità di performance, ovvero in sostanza il mercato dei consumi, dall’altro quelli che venivano utilizzati in presenza della forte aleatorietà legata all’andamento del mercato finanziario.
Spiegami bene: i sistemi di supporto alle decisioni si applicano dove c’è un elemento di incertezza, giusto? Altrimenti non se ne sentirebbe il bisogno: se i pattern sono auto-evidenti, e l’incertezza è minima, che me ne faccio della BI?
Max Cavallo: Aspetta, capiamoci bene. I sistemi esperti iniziali avevano sì un’incertezza, ma legata a come interpretare i fenomeni con una disciplina specifica. Immagina un sistema di regole: se il prezzo scende oltre una certa soglia, acquista; altrimenti no. Il problema stava nel definire un albero decisionale applicabile sia nel mondo ciclico che in finanza. Nel tempo ciclico potevi mettere pesi statisticamente rilevanti a priori; nel tempo lineare, browniano, come quello della finanza, i pesi erano determinati dalla lettura del fenomeno, avvicinandosi ai training set di oggi. Non sapendo mettere i pesi a priori, li facevi determinare dall’analisi di ciò che accadeva.
In seguito, con il tempo, la Business Intelligence si è distaccata dai sistemi esperti, ma negli anni ’80 c’erano i sistemi esperti con alberi decisionali. I dati disponibili erano pochissimi: commerciali, finanziari, contabili, un po’ di logistica. Non c’erano dati chiari sulla concorrenza.
Poi negli anni ’90 ci fu un’accelerazione: si cominciò a parlare di data warehouse perché le aree governate dall’informatica si sono ampliate – logistica, after sales, infrastruttura d’impresa, human resources. Gli strati informativi disponibili sono cresciuti, sempre per analisi interne.
Oggi è ancora diverso, la Business Intelligence è concepita come strumento di misurazione non solo delle dimensioni interne all’azienda, ma anche delle performance rispetto al mercato e alle traiettorie tecnologiche. C’è stata crescita dei dati interni, crescita dei dati di confronto, e oggi si considerano anche le traiettorie tecnologiche future, sempre al fine di non sbagliare le strategie.
Quindi dati interni, dati sulla concorrenza e dati sullo sviluppo tecnologico prevedibile?
Max Cavallo: Esattamente. E oggi questa è la componente più delicata – non solo traiettorie tecnologiche ma anche geopolitiche.
Tornando un attimo agli esordi, parliamo di sistemi esperti perché gli alberi decisionali erano disegnati da umani competenti?
Max Cavallo: Assolutamente, erano disegnati da esperti! Per questo si chiamavano sistemi esperti. Ma come dicevo bisogna distinguere tra il tempo ciclico del mondo commerciale e quello lineare della finanza. Mentre nel commerciale avevi un sistema esperto che ti diceva ‘se succede questo, allora succede anche quello’, come un medico che sa che se hai la glicemia alta devi occupartene, in finanza non sapevi mai esattamente come andava a finire. E qui entravano in gioco il machine learning e le reti neurali che non avevano un modello precostituito, non avevano un esperto che disegnava gli alberi decisionali e cambiava i pesi.
Questo accadeva già negli anni ‘90?
Max Cavallo: Assolutamente. Il mio primo lavoro, laddove ho incontrato Roberto Marchisio che è anch’egli socio di questo Circolo, fu proprio in un’azienda software che lavorava per banche e finanza. Ho trascorso un periodo della mia vita chiuso in una trading room a vedere come lavoravano i trader e trasformare i loro desiderata in software operativi. E già si utilizzavano le reti neurali per cercare di anticipare i fenomeni.
In finanza è così: o hai le informazioni e le domini (ma è rara avis), oppure prendi i dati su quello che è successo e li interpreti con pesi che non dai tu, che non sai neanche perché sono stati conferiti, ma che riflettono questo moto browniano dei dati finanziari. Il modello è una black box: entra un segnale, viene manipolato, tradotto in pesi, dà un output. Quindi già all’origine c’erano questi due modelli: i sistemi esperti legati al mondo ciclico, e quelli neurali legati al mondo browniano, prevalentemente quello finanziario.
Poi negli anni ’90 la Business Intelligence è emersa con dei prodotti specifici. Uno dei primi fu Business Objects. Nel nome si fa riferimento allo schema della modellazione, perché le aziende condividono tutte una stessa architettura di base riassunta nella catena del valore di Porter, la cosiddetta ‘Porter Value Chain’. Porter ha modellato l’architettura profonda di tutte le aziende, di qualsiasi settore, che condividono tutte quella struttura archetipica. Hai sempre gli stessi bucket strategici: Inbound Logistics, Operations, Outbound Logistics, Marketing, Services come macroattività di valore, e sopra si innestano le attività di supporto: Information Technology, Human Resources, Procurement, Firm Infrastrutture.
Perché la Value Chain di Porter è stata così importante?
 Max Cavallo: Dato che queste strutture organizzate sono ripetitive, hanno cominciato a emergere anche modelli di business standardizzati secondo criteri di efficienza ed efficacia. Quando dovevi leggere a consuntivo i dati aziendali, avevi a disposizione dei modelli precostituiti di analisi e misurazione della performance. In altre parole ha cominciato ad emergere una grammatica di base, che inizialmente non è stata interpretata come grammatica ma come metodologia utile a modellare i database. In realtà è una vera e propria grammatica che si estrinseca in dimensioni, gerarchie, relazioni e metriche. Le dimensioni ti dicono la forma del modello che vuoi analizzare; le gerarchie come vuoi sintetizzare i dati (mesi, trimestri, semestri; prodotto singolo, divisione di prodotto; singolo negozio, aree commerciali). Su ogni dimensione si innestano una o più gerarchie di analisi. Una volta definito il modello basato su dimensioni, gerarchie e relazioni, lo devi misurare e innesti un’ulteriore componente di indicatori – i celeberrimi Key Performance Indicator (KPI) che misurano le performance di quel modello.
Max Cavallo: Dato che queste strutture organizzate sono ripetitive, hanno cominciato a emergere anche modelli di business standardizzati secondo criteri di efficienza ed efficacia. Quando dovevi leggere a consuntivo i dati aziendali, avevi a disposizione dei modelli precostituiti di analisi e misurazione della performance. In altre parole ha cominciato ad emergere una grammatica di base, che inizialmente non è stata interpretata come grammatica ma come metodologia utile a modellare i database. In realtà è una vera e propria grammatica che si estrinseca in dimensioni, gerarchie, relazioni e metriche. Le dimensioni ti dicono la forma del modello che vuoi analizzare; le gerarchie come vuoi sintetizzare i dati (mesi, trimestri, semestri; prodotto singolo, divisione di prodotto; singolo negozio, aree commerciali). Su ogni dimensione si innestano una o più gerarchie di analisi. Una volta definito il modello basato su dimensioni, gerarchie e relazioni, lo devi misurare e innesti un’ulteriore componente di indicatori – i celeberrimi Key Performance Indicator (KPI) che misurano le performance di quel modello.
Possiamo chiamarli parametri?
Max Cavallo: Non userei il termine ‘parametri’ perché oggi richiama i parametri dell’AI e creerebbe confusione semantica. Sono proprio indicatori – KPI e driver. Ci sono sia i KPI sia i Key Competitive Factors, che sono due cose differenti. I KPI sono la misurazione oggettiva di un fenomeno letto con indicatori; i Key Competitive Factors sono quegli elementi del business che sono driver della crescita o sviluppo. Esempio: le vendite sono un KPI oggettivamente riconosciuto, come il margine. La brand reputation invece è un Key Competitive Factor. Mentre i KPI sono direttamente misurabili, i KCF sono più intangibili, più di direzione tecnologica.
In questo scenario dove collochi gli ‘ipercubi’ che creaste voi in Hicare negli anni ’90?
Max Cavallo: I cubi sono la componente multidimensionale della grammatica HCR. Nella modellazione dei dati esiste la componente multidimensionale che descrive il tuo mondo attraverso molteplici dimensioni. Facciamo un esempio concreto, che ne so, Unieuro: ci sono le dimensioni point of sales, gamma prodotti, tempo (tempo ciclico con anno commerciale, mesi, giorni – il panettone si vende in certi periodi), storia (gli anni, perché vuoi confrontare gennaio 2026 con gennaio 2025; nonostante si tratti di tempo, è una dimensione ortogonale), data category, eccetera.
Nella semplicità di un’attività commerciale, abbiamo già individuato cinque dimensioni standard applicabili a Unieuro, a Mediaworld, e a tutti gli altri, perché il business in sé è costituito da quelle dimensioni. Al di sopra ci sono le gerarchie per passare dalla sintesi all’analisi. Una volta descritto il modello concettuale, applico i miei indicatori: vendite, margine, sconti, numero di pezzi venduti, che si riferiscono a tutte quelle dimensioni e gerarchie.
Ora, di fatto sto disegnando un poliedro. I cubi non sono cubi, sono poliedri. Ogni organizzazione ha un proprio poliedro. Questa è la grammatica, e posso dirti che in trent’anni applicando quella grammatica in modo rigoroso abbiamo modellizzato praticamente tutto, tutti i settori industriali e le aree aziendali. Abbiamo usato uno spettro di riferimento che abbiamo applicato quasi universalmente senza mai perdere dettaglio.
Dove eravamo inefficaci? Nella finanza, perché lì non c’è una modellizzazione razionale se non a consuntivo. A consuntivo eravamo efficaci, ma a livello preventivo assolutamente no.
Vorrei capire meglio: nei sistemi esperti di solito c’è un reasoner che si preoccupa di eseguire le inferenze in base ai dati disponibili, che nel vostro caso sono resi disponibili nel poliedro o ipercubo che dir si voglia. Se ho capito bene invece, nel caso della Business Intelligence, il reasoner è il cervello dell’amministratore delegato o del top management che si preoccupa di fa inferenze sui dati del poliedro. È giusto?
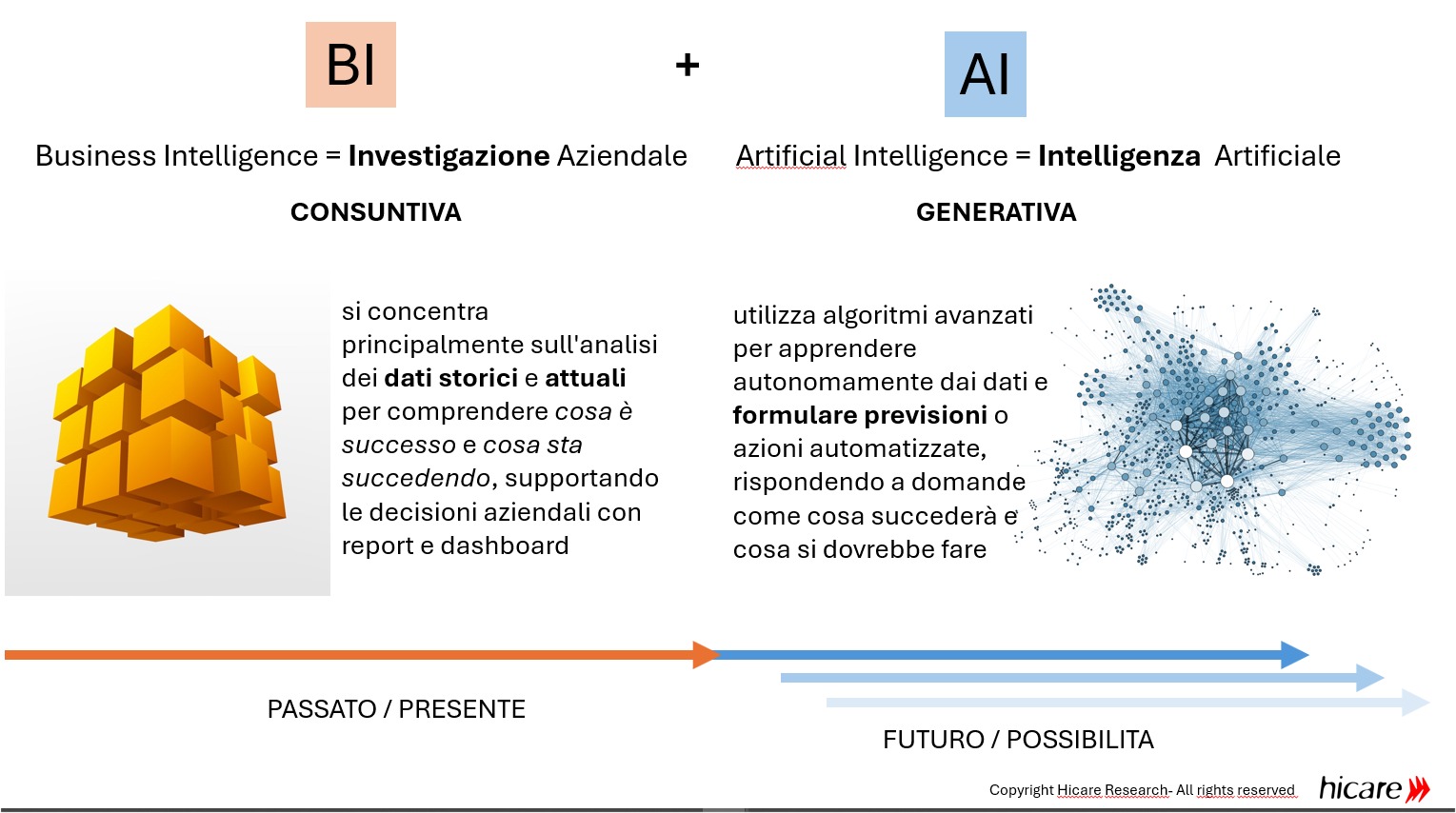
comparazione Business Intelligence e Artificial Intelligence
Max Cavallo: Sì, le inferenze le fa necessariamente il decisore. Questo è il passaggio sostanziale, perché la Business Intelligence non vuole fare il sistema esperto. La Business Intelligence non vuole affatto sostituirsi al decisore. Nell’espressione ‘Business Intelligence’, l’intelligence non è quella di ‘Artificial Intelligence’, laddove intelligenza sta appunto per capacità inferenziale e di apprendimento. No, qui intelligence sta per indagine, inchiesta, investigazione.
Io sono il decisore e ho miliardi di dati organizzati per pillar. Ho bisogno di un sistema che mi permetta di vedere la mia azienda tutta intera con i miei occhi. Se ad esempio vado a vedere le fatture che ne so, di Stellantis, devo confrontarmi con milioni di documenti che vanno a costituire il dato di fatturato? No, sarebbe del tutto incongruo, ho bisogno di un sistema che raccolga tutti i dati granulari e me li metta a disposizione dentro a una struttura di riferimento attraverso la quale valuto l’azienda.
Non tutti i manager sono capaci di valutare autonomamente i dati messi a disposizione dalla BI, alcuni in effetti non sono capaci e vorrebbero essere aiutati da un sistema esperto o simili. Anche per questo sono nati vari modelli di BI: consultiva, descrittiva, simulativa e prescrittiva. Per agevolare questo tipo di manager senza capacità di visone autonoma dei dati, prima della rivoluzione AI si è provveduto a implementare dei sistemi esperti che dicevano: ‘se aumenta questo devi fare questo….’ Beh, personalmente li considero la negazione dell’intelligenza di business e della managerialità.
E se invece prendo un modello di Ai generativa contemporaneo, per esempio Claude Sonnet 4.5, e gli faccio masticare il tuo poliedro, questo potrebbe essere utile?
Max Cavallo: Questo sì che ha senso, questa è la nuova frontiera! Come dicevo sono stati fatti (non da noi ma sono stati fatti) dei tentativi per trasformare le applicazioni BI in sistemi esperti capaci di fare inferenze, ma i risultati sono stati deludenti.
Adesso invece cambia la musica perché è arrivato qualcosa che sembra fatto apposta per ‘masticare’, come dici tu, i dati dei nostri poliedri e restituire della conoscenza di livello superiore. Ci sono dei passaggi da fare, tutt’altro che banali, ma sicuramente ha senso farli, perché abbiamo a che fare con un game changer.
Il primo passaggio consiste nel sostituire esperti come Max Cavallo o Roberto Marchisio nella modellazione. Per noi è naturale raccogliere dati sparpagliati e costruire cubi o poliedri, abbiamo questa grammatica in testa e una tecnologia costruita su quella grammatica. Trasformare dati che arrivano da 14 database diversi in 13 formati diversi in un poliedro per noi è semplice. Però impieghiamo almeno due anni per formare una persona a svolgere quel compito, e poi ci mettiamo una settimana per modellare i cubi.
Se invece uso l’AI per modellare impiego molto meno tempo, ci guadagno forse anche in precisione, e con questo sono a metà del guado.
Poi c’è un secondo passaggio: l’AI è determinante perché quei dati nel cubo li devo rendere in forma grafica. Ci sono una quarantina di forme grafiche che sono nate per rappresentare fenomeni specifici, e noi possiamo istruire l’AI ad applicare queste forme secundum artem.
Qui però stai parlando di dati strutturati, giusto? Dati che hanno già un loro ordine nel momento in cui vengono dati in pasto all’AI.
Max Cavallo: Sì, è così. Il vantaggio delle reti neurali e dell’analisi big data è che a volte scopre relazioni emergenti che all’occhio umano sfuggono, ma non siamo ancora lì. Quando si parla di big data, data lake, data reservoir, si parla di dati destrutturati che magari provengono dalla rete. I big data sono più afferenti al mondo esterno alle aziende che a quello interno. Le aziende hanno anche molti dati destrutturati, ma dobbiamo chiarire cosa vuol dire ‘destrutturato’, perché a volte con questo termine ci si riferisce ai metadati.
Aspetta, io sono abituato a usare il termine ‘metadati’ nel mondo SEO, ma ho l’impressione che tu qui intenda qualcosa di diverso…

Dati e Metadati
Max: Metadato viene dal greco: meta, per mezzo di. Il dato è il fatto, l’evento. 1.300 euro è il dato. Cos’è questo 1.300 euro? Di cosa sto parlando? Prima di tutto c’è un’unità di misura – primo metadato, una grandezza. L’unità di misura dice ‘euro’, quindi so che è una valuta. Devo aggiungere altri elementi descrittivi che contestualizzino il dato – il contesto. Il metadato è appunto ciò che ‘descrive’ la natura del dato. Facciamo un esempio concreto di MediaWorld: il dato singolo è iPhone 17, Torino Porta Nuova, 4 febbraio 2026, ore 15, cassa 2. L’etichetta delle colonne del database è la dimensione – si chiamerà ‘prodotti’. iPhone 17 è il metadato, la colonna è la dimensione.
Se iPhone 17 è il metadato, il dato è?
Max Cavallo: in questo esempio 1.300 euro, ovvero il fatto. Prima descrivo il modello concettuale – prodotto, negozio, tempo, momento storico – poi il fatto è 1.300, e c’è un KPI che misura il fatto. I metadati sono tutti i dati di framing che permettono di interpretare l’informazione, compreso il KPI che è anch’esso un metadato.
Quando si fa il data lake, spesso questo modello concettuale non c’è, mentre i metadati sono presenti. Quindi non si tratta di dati destrutturati, ma semplicemente di dati non modellizzati. Li hai messi dentro a un bacino, ma non sono destrutturati. Un dato destrutturato invece manca di alcuni metadati, quindi deve essere interpretato prima di essere modellizzato.
Quindi distingui tra mancanza di metadati (destrutturazione) e mancanza di modellizzazione, che è altra cosa.
Max Cavallo: Esattamente. Sono livelli di intervento diversi. Semplifico molto perché qui c’è letteratura accademica che distingue data lake da data reservoir: il data reservoir ha già i tag, il data lake no.
Quindi, tornando a bomba, una cosa sono i dati di contestualizzazione (metadati), altra cosa è il modello che lavora su questi dati per costruire un sistema. Il poliedro lo puoi considerare un contesto sistematizzato, un contesto restituito completamente, senza ambiguità. Il contesto riflette il modello di business del decisore, a cui semplifichi la vita perché coaguli intorno alla sua visione tutti quei dati atomici, granulari, sparsi, differenziati in metadati, che altrimenti resterebbero non-interpretabili. Uno dei grandi lavori della BI, direi l’80% del totale, consiste proprio nella transcodifica, non leggere la stele di Rosetta. Quando hai dati che provengono dalla Cina, dal Bangladesh e da Moncalieri, hai le informazioni potenziali ma disperse dentro a un caos totale, e devi ricondurre il tutto a un contesto interpretabile.
A volte è anche un problema di interpretazione dei bilanci. Uno dei progetti di Adidas si chiamava One Version of the Truth, perché in CDA arrivavano con tre dati diversi di vendita che ballavano per 300-400 milioni.
Ma le vendite sono la raccolta degli scontrini, come fanno a ballare 400 milioni?…
Max Cavallo: Non è così semplice. Devi chiederti: come sono trattati i resi? Come è trattato il furto? Sono possibili interpretazioni diverse di tutti questi fenomeni. Non c’è One Version of the Truth perché non c’è una grammatica aziendale sufficientemente consistente e coerente per dare origine a un dato univoco. Detta diversamente, le varie componenti dell’azienda non sono d’accordo sul dizionario interpretativo. La Business Intelligence interviene in queste situazioni creando metadati assolutamente consistenti e coerenti. Qui si parla di Master Data Management, il grande dizionario unificato che deve produrre la fatidica One Version of the Truth.
La verità però è che gran parte delle aziende questo dizionario unificato non ce l’ha. E allora alcuni dicono: “non siamo riusciti a fare niente con la BI perché era sbagliata, troppo complicata, non si poteva applicare, ma ora useremo l’Artificial Intelligence che farà tutto lei”. Ecco la fesseria del secolo. Quando fallisci nell’interpretazione di un fenomeno e ti butti su una cosa che sulla carta è risolutiva perché fa tutto lei, non può mai funzionare.
Di fatto ci sono tre o quattro diversi livelli nei quali è possibile far lavorare efficacemente l’AI. Si parla di intelligenza artificiale con gli agent che vanno a sostituire il lavoro della BI, ma veramente non si capisce come lo stiano interpretando. Per come la vedo io, bisogna applicare l’AI per step successivi: innanzitutto nella interpretazione delle informazioni che arrivano, e quindi nelle analisi semantiche, nel linguaggio. Lì applico l’AI per ricondurre tutto a un linguaggio unico – ad esempio l’inglese. Tutto ciò che arriva da fuori lo interpretiamo e lo dotiamo di un’architettura linguistica omogenea. Così lavoriamo sul metadato e sull’interpretazione del metadato.
Un altro ambito in cui l’AI funziona bene è quello della modellazione. Ho una certa expertise nella modellazione, e oggi uso l’AI insieme a un sistema esperto – che in fin dei conti sono io con le mie competenze – per trasformare quell’informazione in un modello. Dopo aver generato il modello, posso dotarlo di un formato grafico, scegliendo insieme all’AI il formato giusto – un Sankey, un Gantt o altro a seconda dei casi.
L’altro utilizzo è quello cui facevi riferimento tu: dò in pasto all’AI un modello già definito, strutturato ed efficace, per interpretare il futuro. Ma a quel punto quelli sono dati organici, puliti. Il training set che dò in pasto all’AI è un diamante, non un big data da cui magari ricavo correlazioni interessanti ma mi perdo l’essenziale.
Una bella frase che ha detto Roberto Marchisio quando ci siamo rincontrati dopo un po’ di anni durante i quali lui si era buttato sull’AI e io invece avevo proseguito secondo la via, per così dire, ortodossa, è questa: “C’è tanta fuffa, perché è come il mito della caverna”. Credo lui volesse dire che vai a usare l’AI per vedere le ombre quando in realtà hai già a disposizione gli oggetti fungibili che devono solo essere modellizzati. Ecco, non ha senso usare l’AI in quel modo.
Ha senso usarla se costruisci modelli strutturati e fai fare training all’AI su quei modelli strutturati, applicando la grammatica. L’AI ti serve a scegliere i poliedri, ma poi i dati sono poliedri, non sono LLM, non sono Large Language Model. Una cosa è il modo in cui vengono trattati i dati, un’altra cosa è il modo in cui viene trattato il linguaggio. Il linguaggio deve essere usato solo per arrivare ai metadati che ti portano al dato, ma il dato poi deve essere lavorato con l’algebra lineare, con la grammatica, con la matematica, con le funzioni, non con un Large Language Model.
Non mi serve la simulazione di un bilancio costruita su elementi verbali, voglio una simulazione di un bilancio costruita su un poliedro. Anche se è vero che utilizzo i metadati e l’intelligenza artificiale per indicizzare, organizzare, fare la scelta del modello giusto di simulazione.
È lì che oggi si fa molta confusione. A parte i pochi documenti tecnici approfonditi, per il resto c’è una superficialità incredibile. Si confonde l’AI che ti crea l’immagine realistica del cane con sei zampe con quella che fa l’agent di McKinsey per guadagnare cifre astronomiche in un lasso di tempo limitato.
Alla fine, però, correggimi se sbaglio, questo quadro che stai facendo – che prevede modelli generati secondo le vostre competenze tecniche, e poi successivamente dati successivamente in pasto a sistemi di intelligenza artificiale, che non sono Large Language Models ma altre specialità dell’AI – alla fine è sempre un sistema esperto. Ho un modello creato dall’uomo che dò in pasto all’intelligenza automatica. Quindi alla fine siamo arrivati a un sistema simbolico, perché il poliedro è una caratterizzazione simbolica. A me sembra che qui rientramo nel filone di quella che viene definita AI simbolica, o forse meglio una combinazione di AI simbolica e di AI connessionista (deep learning). Yann LeCun, uno dei creatori delle reti neurali convoluzionali, afferma esattamente che il futuro dell’intelligenza artificiale risiede proprio nell’ibridazioni tra sistemi esperti e AI generativa.
Max Cavallo: Sono d’accordo, e nel nostro caso questi ibridi sono i cosiddetti RAG neurosimbolici (GraphRAG, SymRAG, NeuSym‑RAG, eccetera). Non i Rag ‘vanilla’, in cui la componente simbolica è molto scarsa…
Veniamo alla rivoluzione che state preparando: puoi spiegarmi in parole adatte a un profano di che si tratta?
Max Cavallo: Abbiamo due prodotti: uno destinato alle aziende e l’altro al pubblico generalista, per intenderci un’applicazione tipo Canva. Quello per le aziende si chiama Luna 10, mentre quello destinato al pubblico ampio non ha ancora un nome commerciale, ma solo un codename…’Toronto’.
Quando parli di democratizzazione dei sistemi BI, parli di Toronto?
Max Cavallo: Esattamente. Toronto è un prodotto per cui tu – profano come ti sei autodefinito – hai a disposizione un tuo sistema che non ti aiuta a disegnare slide, ma ti aiuta a creare una vera e propria dashboard BI. Hai quel maledetto foglio Excel molto complesso che non sai interpretare, non sai cosa farci, non sapresti neanche ricavarne un graficuccio…. E allora che fai? E allora fai un upload su Toronto – vai su toronto.hicare.com, clicchi ‘upload your file’, carichi il foglio maledetto e poco dopo ti compare la tua dashboard con quei dati interpretati. Non male no?
Wow, ne avrei di roba da mettere lì dentro!
Max Cavallo: Un sacco di gente è nella tua stessa condizione. Chiaramente con tutti i limiti del caso, ma si tratta di un sistema per cui se hai un insieme di dati che non sei in grado di interpretare – può essere un foglio Excel, CSV, qualsiasi cosa – lo dai in pasto a Toronto, che che in pochi secondi ti crea una dashboard con la contestualizzazione e la modellizzazione di questi dati.
Come lo metterete sul mercato? Gratuito, freemium, premium…
Max Cavallo : Siamo a tanto così da finire il prodotto, lo stiamo già testando, ma il problema è che costa un botto sia di storage che di digital marketing. Siamo in un cul-de-sac perché il prodotto ha bisogno di un finanziatore per andare sul mercato. Per questo abbiamo due linee: trovare un finanziatore per Toronto potrebbe richiedere tempo, quindi per il momento andiamo a mettere le feature sviluppate per Toronto in Luna 10, l’applicazione dedicata alle aziende. Il modellatore automatico, la dashboard automatica e tutto il resto, possono far comodo anche alle aziende. Invece di chiamare i consulenti, fai l’upload del file e hai subito la dashboard a disposizione. Soprattutto alle PMI questa soluzione può far molto comodo. Il paradosso è che potenzialmente se hai successo rischi di avere un problema di gestione dati a livello di server.
Direi che è un happy problem…
Max Cavallo: Certo, quando sei in quella situazione è il finanziatore che viene a cercarti, non viceversa. Se azzecchi la cosa e cominci ad avere un certo numero di utenti non hai più un problema, perché il business è chiaramente scalabile. Devi pensare che Toronto per il pubblico generalista è una applicazione da 50-70 euro al mese, è per tutti.
Fermi tutti, 50-70 euro al mese? ChatGpt o simili al livello premium costano mediamente una ventina di euro al mese. 50-70 euro è già un altra spesa…
Max Cavallo: Sì, ma prevediamo diversi livelli. C’è un livello premium dove puoi fare tante operazioni, e poi hai gli add-on: vuoi i dati della FAO? Vuoi dei dati di confronto con il mercato di riferimento? Lo scopo di questo sistema non è solo mettere a disposizione una dashboard, per efficace che possa essere. In realtà c’è molto di più… basta pensare che abbiamo impiegato due anni per costruire un dizionario di metadati generali per il business. Quando arriva un dato, so subito dove metterlo. Non posso usarlo sic et simpliciter per motivi di privacy, ma posso fare medie di settore di dati che arrivano da tutto il mondo. Toronto sarà diffuso in 11 lingue, ed essendo cloud, arriveranno dati di settore dal Giappone o dalla Cina che nessun altro può metterti a disposizione.
Vediamo se ho capito bene. Voi avete la vostra attività in cui vendete alle aziende i vostri servizi di BI, che definiamo tradizionali nel senso che fate questa cosa da tanti anni, ma ora andate sul mercato retail con questo prodotto innovativo. Immagino che nell’architettura di Toronto ci siano istruzioni di modellizzazione esperte, che costituiscono la vostra esperienza accumulata negli anni. Poi utilizzate un database o repository HCR, che è il vostro cavallo di battaglia – un database fatto apposta per fare BI ad alto livello. Avete le vostre procedure di modellizzazione, i vostri modelli, e poi utilizzerete un motore AI Per dare la risposta…
Max Cavallo: In realtà più livelli di AI. Prima c’è l’interprete. Arriva il dato cinese e devo trasformarlo in inglese, anzi in realtà non solo trasformarlo in inglese, ma dargli la semantica di business, l’intestazione delle colonne. Poi c’è un secondo livello che si chiama modeler. C’è la parte di interpretation, ingestion e modeling. Lì c’è il sistema esperto, il RAG, che comprende anche un LLM e consente trasformazione in cubo, o poliedro come preferisci. Poi, una volta che i dati sono nel cubo, chi sa fare il grafico dal cubo? Noi. A quel punto facciamo un secondo sistema esperto che ti disegna la dashboard. Ci sono dati geografici? Ci metto la mappa. Ci sono dati di vendita? Ci metto un grafico eloquente. Quindi: interprete, modellizzatore, visualizzatore. Poi abbiamo una componente premium: Sei nel settore metalmeccanico e ti interessa analizzare i dati sulla metalmeccanica nel mondo? Abbiamo a disposizione tutti gli open data dalle varie databank, e ti facciamo un bel un grafichetto.
Allora l’AI connessionista, il deep learning sta innanzitutto nell’interpreter, giusto?
Max: Sì, nell’interpreter c’è.
Nel modellizzatore?
Max Cavallo: No, perché è un RAG. Non è esattamente AI come la interpretiamo noi – non solo è supervisionato, è proprio un RAG.
L’ultimo passaggio, la visualizzazione, è di nuovo un sistema esperto.
Max Cavallo: Giusto, quindi per ora di machine learning vera e propria ce n’è abbastanza poca. Ce ne sarà di più in futuro, per la simulazione da quei dati. Allora sì che andremo a prendere i dati dai cubi e li daremo in pasto alla macchina per generare delle simulazioni complesse. Ma è un passaggio che oggi come oggi ancora non c’è, e che potrebbe interessare prima Luna, il prodotto per le aziende, piuttosto che Toronto.
Quale modello AI state usando? GPT, Gemini, Claude?
Max Cavallo: Per ora stiamo usando Llama. quello di Yann LeCun, che è open source. Lo usiamo per ragioni di sostenibilità commerciale, perché andare a mettere delle API su AI di mercato ci taglierebbe le vene…
Vorrei capire meglio un altro aspetto, il cuore della macchina, il database che è una vostra creatura, ovvero HCR, che sta per Hierarchical Cartesian Relational. Hai voglia di descrivermelo, differenziandolo dai database relazionali, multidimensionali? In cosa consiste, cosa lo caratterizza?
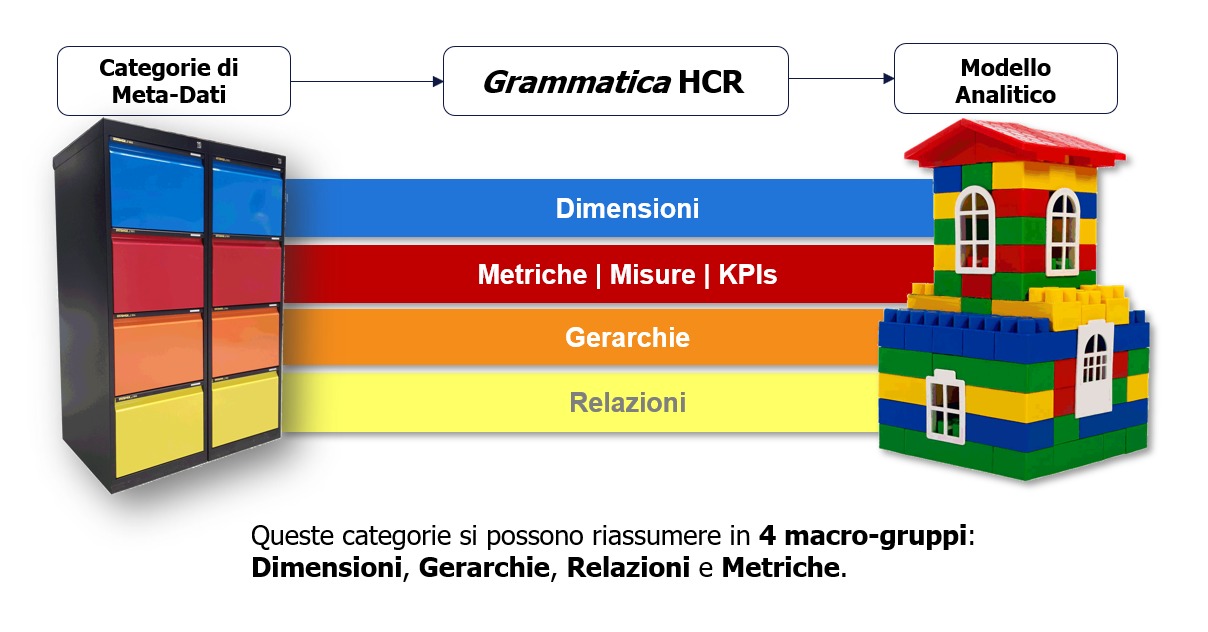
Grammatica HCR
Max Cavallo: In realtà fondamentalmente è un ibrido. Non è che gli altri database siano inefficaci o inefficienti, fanno bene il loro lavoro in determinati ambiti. Un database relazionale oggi è la migliore architettura che esiste per trattare le transazioni, non c’è niente di meglio al mondo. Il problema è che se metti delle righe in append, questo non è quello che serve a un decisore, che ha bisogno di sintetizzare le informazioni. Sintesi, confronto e misurazione sono le attività di base che un decisore deve svolgere per esplicare al meglio la sua attività discrezionale. A lui devi offrire un modello multidimensionale, perché i dati per origine, che sono gestiti egregiamente da un db relazionale, devono essere trasformati in dati per destinazione in un appropriato contesto di business. Un modello multidimensionale classico, come quello dei MOLAP, aveva grossi problemi: i MOLAP erano monocubici, monotipo, alla fine esplodevano. Offrivano grandi vantaggi in sede di analisi, ma andavano in crisi con grossi volumi dati, perché non gestivano le relazioni. Era necessario un motore unico che fondesse le prerogative relazionali con quelle multidimensionali e quelle gerarchiche. L’architettura del back-end è stata pensata solo ed esclusivamente per gestire le analisi.
Ti faccio una domanda maliziosa: non hai paura che attraverso Toronto, magari proprio i sistemi di intelligenza artificiale possano dedurre i modelli applicati per generare le dashboard, che di fatto sono parte del vostro know-how?
Max Cavallo: Certo, ma ormai quei sistemi non hanno più bisogno dei cubi, perché hanno potenza infinita di calcolo. Se prendi SAP HANA che gira su 12 server – spendi un milione a server, con 50 milioni metti in piedi questo sistema e non hai bisogno di nessun cubo. A chi serve il cubo? Ai relativamente poveri, come noi, perché ottiene dei buoni risultati attraverso una tecnologia di mercato sostenibile. Ciò che tempo addietro costava a una corporate 500 mila euro, oggi fondamentalmente lo regaliamo… Ecco la data democratization di cui parlavamo. Di fatto non regali la tecnologia, ma l’accesso alla tecnologia che è mediata da un robot che fa la parte difficile di modellazione. Alto valore a basso costo.
Mi viene da pensare che questo processo democratizzazione dei dati potrebbe essere un antidoto al grande problema della nostra epoca, che in realtà non sono le fake news, ma l’ipertrofia informativa. Siamo massacrati di notizie, subiamo un overload informativo spaventoso che genera moltissimi problemi. Il vero problema è sceverare il grano dalla pula. La gente non riesce più a metabolizzare le informazioni e cogliere l’essenza dei fenomeni, si profonde in eloqui interminabili. Anche per questo viviamo in un’epoca di logorrea diffusa, collettiva.
Max Cavallo: Tu parli di ipertrofia o bulimia informativa, ma in realtà quella lì non è vera informazione, non assurge quasi mai al rango della vera informazione. In informatica si parla di facts table, la tabella dei fatti, degli eventi reali, e alla fine è ciò che conta davvero. Invece quando ascolti un telegiornale ti accorgi che confondono i milioni con i miliardi di euro, topiche di questo genere. Sono pochi i giornalisti che ti presentano, spiegandola, una seria tabella di numeri. Gli unici dati che ti passano sono quelli della disoccupazione.
Alcuni lo fanno, mi viene in mente la Data Room della Gabanelli…
Max Cavallo: Certo, ma vengono stigmatizzati, perché nel momento in cui torni ai numeri, sei misurabile. Tutto quello che si vuole fare oggi è non rendere misurabile il fenomeno. Se ascolti i telegiornali, noi siamo tra le prime economie al mondo, quando in realtà ci troviamo in una situazione di terribile recessione. Se presentassero i numeri veri dei fondamentali economici, che invece quasi nessuno riporta, la gente si accorgerebbe che siamo alla canna del gas, che non abbiamo scampo. Ma naturalmente è una narrazione che non può passare, che nessuno è disposto ad ascoltare.
Ti faccio un esempio concreto, uno tra i tanti: stiamo spendendo 240 miliardi in tre anni con il PNRR. Hai visto un numero, uno solo, da qualche parte, una dashboard che ti dice che questi 240 miliardi sono stati spesi X qui, Y là, e Z qua? I dati ci sono ma non è facile metterli in ordine, farli parlare, e un po’ per questo, un po’ perché forse non c’è una forte volontà di farlo, nessuno o quasi ci racconta come stanno veramente le cose. Me lo prendo come impegno: appena ho un mesetto libero, scarico tutti gli open data, li metto in ordine e li rendo pubblici.
Ma dove si scaricano questi dati?
Max Cavallo: Cerca online ‘PNR open data’, e trovi tutti i file. La cosa difficile è che qualsiasi voce di spesa fa riferimento a un CUP e quindi del CUP devi leggerti il bando, devi riuscire a capire di cosa si sta parlando. Però le tabelle sono lì, a disposizione. La questione è che parliamo di 240 miliardi, equivalenti a 12 manovre finanziarie da 20 miliardi, e nessuno ci dice dove vengono spesi questi soldi. O meglio, i dati ci sono, ma per capirci qualcosa devi fare sforzi osceni.
Ho visto che nell’area piemontese abbiamo speso 268 milioni di PNRR per l’agricoltura, ma in che relazione stanno questi 268 milioni con i 240 miliardi complessivi? Torino e Piemonte non sono mica irrilevanti! In totale, considerando tutti i settori si parla di non più di 1,7 miliardi complessivi per il Piemonte. Stiamo parlando di 240 miliardi di spesa, un fenomeno epocale, e con tutto questo noi siamo allo 0,7% di crescita annua. L’anno prossimo che non ci sarà il PNRR, togli al PIL italiano 240 miliardi, e vedi che numero viene fuori.
Con tutto questo, lo spread BTP-Bund è al minimo storico…
Max Cαvallo: Ma lo spread è governato dalle dinamiche finanziarie, da chi gestisce i grandi fondi che ha tutto l’interesse a sostenere questa narrazione tout va bien Madame la Marquise… Il rating passa da stabile a positivo, ma è chiaro che questa gente ha venduto l’anima al diavolo… I 6000 miliardi di incremento previsti da McKinsey per il prossimo futuro grazie alle nuove tecnologie AI sono divisi tra 12 persone al mondo. Tutto l’incremento di produttività va a finire nelle tasche dei turbo-capitalisti, dei neocon che hanno inventato questo modo di fare soldi. È semplicemente un modo per impoverire e controllare le masse. E diciamola tutta, non ci piace sentircelo dire, ma in Cina stanno facendo un altro discorso, perché lì c’è una vera politica di redistribuzione.
Loro hanno capito tutto: nel momento in cui hai 1 miliardo e 400 milioni di persone di middle class contro 350 milioni di americani e 450 milioni di europei, ovvero contro un miliardo scarso di occidentali, a quel punto hai 1 miliardo e 400 milioni di persone libere, magari non del tutto, ma almeno libere economicamente. E da quella posizione domini il mondo. Qui avremo un manipolo di cresi assoluti e una middle class sempre più povera, mentre di là saranno 1 miliardo e 400 milioni di persone economicamente libere. Non so se mi spiego… A questo serve la data democratization, la BI a portata di tutti o quasi tutti, anche per questo mi piacerebbe che Toronto potesse servire ad aprirci gli occhi e farla finita con le favolette che ci vengono propinate. Freedom now, diceva qualcuno.